agent-vision-mcp:为纯语言 Agent 提供视觉能力
介绍 agent-vision-mcp 项目——一个开源的 MCP 视觉工具,为 AI Agent 提供图像分析、OCR、多图对比等能力,支持任何 OpenAI 兼容的视觉模型。
一句话概括
agent-vision-mcp 是一个开源的 MCP(Model Context Protocol)服务,为 AI Agent 提供视觉fen'xi的能力——分析、OCR、裁剪、多图对比,一行命令就能接入。
Github项目地址:https://github.com/idealizing/agent-vision-mcp
PyPI 包名:agent-vision-mcp
为什么需要这个工具
AI Agent 目前最大的能力短板之一就是无法理解图像。大语言模型本身是纯文本的,虽然 Claude、GPT-4 等模型支持多模态输入,但模型调用和工具链之间的集成并不顺畅。
MCP 是 Anthropic 提出的 AI Agent 工具协议,可以理解成「AI 世界的 USB 接口」——任何支持 MCP 的 Agent(Claude Code、Cursor、各类自定义 Agent)都可以插上同一个工具来使用。
agent-vision-mcp 就是这个生态里的视觉模块,让 Agent 能够:
分析截图和 UI:自动识别布局、组件、错误提示
提取文字(OCR):从图片中读取文字,支持表格转 Markdown
对比多张图片:找出增删改变化
放大查看细节:用归一化坐标裁剪任意区域
使用示例
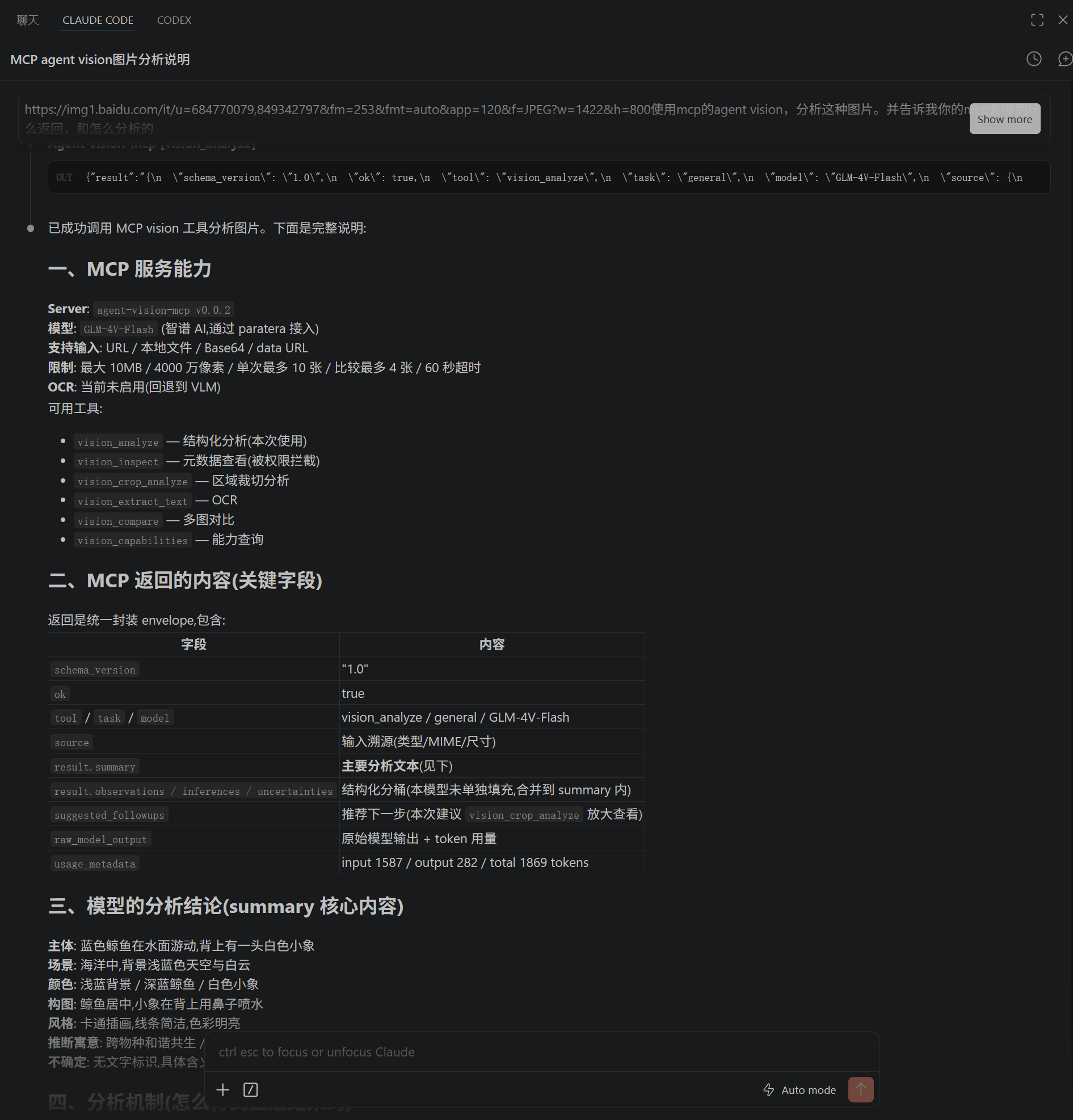
核心设计:三层响应结构
最近做了一次大的重构,把工具的输出格式统一为三层 envelope,这是我觉得值得拿出来说的设计。
第一层:统一信封
{
"schema_version": "1.0",
"ok": true,
"tool": "vision_analyze",
"task": "general",
"model": "GLM-4V-Flash",
"source": { "type": "url", "mime_type": "image/png", "width": 1200, "height": 800 },
"sources": [],
"result": {},
"warnings": [],
"raw_model_output": null,
"error": null
}
成功时 ok: true,失败时 ok: false。所有顶层字段永远存在(空数组、null 都不省略),Agent 消费时不需要 dict.get() 防御。
第二层:按工具定制的 result
不同工具有完全不同的 result schema:
vision_analyze:{summary, observations[], inferences[], uncertainties[], suggested_followups[]}vision_extract_text:{text, blocks[], layout_preserved, unclear_segments[]}vision_compare:{summary, differences[], same_elements[]}vision_crop_analyze:{crop: {x,y,w,h}, summary, observations[]}
第三层:自然语言保留
summary 字段保留模型的完整自由文本。我们没有把模型输出强行塞进固定的枚举结构,而是让 observations、inferences、differences 等结构化字段暂时为空——不伪造结构——等后续有真正的 parsing 逻辑后再填充。
安全和隐私考虑
几个我们特别关注的点:
不暴露 API 密钥:raw_model_output 默认关闭(include_raw=false),开启后也只保留白名单字段(model_name、finish_reason、token 用量),HTTP 头、request_id、签名 URL、异常原文都在进入 envelope 之前就被剔除。
不暴露文件路径:source_ref 默认关闭。URL 只保留 host/path、本地文件只保留 basename。data URL 和 base64 输入则完全不暴露。
URL 安全检查:下载图片时检查重定向目标是不是私网地址,防止 SSRF。
快速上手
claude mcp add --scope user agent-vision \
VISION_API_KEY="your-api-key" \
VISION_BASE_URL="https://your-provider.example/v1" \
VISION_MODEL_ID="glm-4v-flash" \
-- uvx agent-vision-mcp
之后在 Claude Code 里直接说:
用 vision_analyze 分析这张图片
或者更具体地:
对 /data/screenshot.png 用 vision_inspect 查看尺寸,再用 vision_analyze 按 ui 任务类型分析
目前支持的视觉模型包括 GLM-4V-Flash(智谱)、GPT-4o、Qwen-VL 等所有 OpenAI 兼容接口的模型。
结语
agent-vision-mcp 是一个小而专的工具。它不做「AI 平台」那种大而全的事,而是专注于做好一件事——让 Agent 能看。三层 envelope 的设计思路也希望能给其他 MCP 工具的开发者一点参考:稳定的 wire format 对于 Agent 生态的可组合性至关重要。
如果你有兴趣,欢迎去 GitHub 看看,提 issue 或 PR。